A friend of mine broke a badminton racket during a match, and I was struck by how the sharply bent and twisted metal rim was transformed into a smooth, continuously double-curved surface by the racket weave. I looked closely at the balance of tension in the woven cord, thought of how it resembles Poisson's equation, and suddenly it all made sense.
Hmmm, this looks more like a minimal surface, i.e. a solution to the minimal-surface equation[0], than a solution to Poisson's equation. Then again, both equations are of elliptic type.
Some links for people who've never heard of minimal surfaces:
Isn't Poisson's equation basically describing a minimal surface for small z?
I'm not saying the badminton racket follows exactly a (discrete) 2D Poisson equation. But it's certainly related enough to be more than a surface similarly.
The cords are under high tension, which means that any curvature along x (that is, dz^2/dx^2) will result in a net z-axis tension force unless balanced by an oppositely curved cord running in the y direction. Since it's in static equilibrium, there can be no unbalanced forces and so that must be the case. Therefore at each intersection, (d^2/dx^2 + d^2/dy^2)z = 0, which is Poisson's equation in 2D for z height being the function. Approximately, assuming equal tension in x and y, small z, and so on.
I think that is good intuition. The transverse force is the second derivative of the transverse position, to first order. But then there are higher order effects in it. I think that is where that math breaks down.
If you want to get technical, this isn't a continuous surface but weave of strings. And something that makes this more complex is the location of the string intersections has a static/dynamic friction component that is difficult to model analytically. But I think we accept your approximation if you are looking for numeric results.
I think this is a beautiful article. There's code, there's math. There are many plotted examples using a variety of different plotting techniques (in total, representing a 2d array as data, or in black/white, or with a terrible 'jet' colormap, or as a 3d terrain.
Why is the laplacian so ubiquitous? Well, locally any reasonable PDE is well approximated by a linear one. And linear PDEs are of the form Lu = f for a linear differentiable operator L. But why does the particular case of L = laplacian show up so often in physics? Galilean invariance says that the laws of physics should be invariant under translation and rotation. Checking this against Lu = f, you can verify that one requires that L commute with translations and rotations. That is L(u_h) = (Lu)_h, where u_h(x) = u(x+h), and similarly for rotations. What you can show (pretty easily on the Fourier side) is that every linear differential operator with these properties is a polynomial in the Laplacian.
> you can show [...] every linear differential operator [that commutes with translations and rotations] is a polynomial in the Laplacian.
I may be tripping over something here but this doesn't sound right. If you mean polynomial in the real number sense, i.e.
Lu = a0 + a1 Delta(u) + a2 Delta(u)^2 + ...
(where Delta = Laplacian, and a0, a1, ... real numbers), then is this true? The famous wave operator doesn't have this form.
And if you mean "polynomial" as in a series over function space, i.e.
Lu ~ a0 + a1 Du + a2 D^2u + ... (infinite terms, not equality but convergence)
where D is the usual differential operator and a0 is a number, a1 is a 1-d vector, a2 is a 2d matrix, so on, then this is standard calculus of variations on any reasonable function space. Taylor series for function spaces if you want. I don't think that's limited to nice Galilean operators.
Thanks for pointing this out, I should have been more precise. I was referring to time invariant equations. You are right that this doesn't apply to the wave operator (which also does not commute with rotations in R^4). But in space only, yes polynomial means polynomial with constant coefficients.
The proof basically goes that commuting with translations implies immediately that L has constant coefficients. Then on the Fourier side applying L translates to multiplying by a polynomial, and commuting with rotations translates to the claim that that polynomial is rotation invariant. And every rotation invariant polynomial in several variables is p(|x|^2) for some polynomial p in on variable. Then on the spacial side p(|x|^2) translates to L = p(laplacian).
My (unorthodox and somewhat rickety) note-taking gizmo uses Poisson's equation to classify (continuously) entries.
Basically the note-taking gizmo is a graph. Nodes are given conceptual masses either through pagerank or betweenness centrality (i.e. either through how many random walks or how many shortest paths cross a node). Then we calculate a potential energy (gravity potential) if we by inverting the graph laplacian (a few methods are available). Special attention is given to nodes that "float the most.
That looks really cool -- I presume it has some way to enter more than a single word/phrase in a node? Not sure linking individual words is useful for me :-) I should just try it, of course...
The article never explains why ∇2 means "average of neighbors". It's the divergence of the gradient, which is (one kind of) n-dimensional 2nd derivative.
In a one-dimensional function, the second derivative is 0 when there is no curvature, aka a straight line (of any slope), and any point on a line is equal to the average of its neighborhood. A plane also has this property, but in 2+ dimensions you can also make other shapes (like saddles), that are made up of lines (like a plane) but the lines are twisted relative to each other in interesting ways (like "string art"). You can also visualize (aka impose a coordinate system for) these surfaces as having positive curvature (concave up) in one direction, and exactly opposite negative curvature (convex up, or concave down) in the orthogonal direction, summing to 0.
The notion that the simple Laplace solver can scale to grids of arbitrary size, without modification, is a bit misleading for practical purposes. Computational performance will tank or zero out if memory hierarchy constraints are not considered. The author does mention high-performance solutions like multigrid. However, even a basic successive overrelaxation algorithm like the one shown can be partitioned and parallelized, and it is a very good programming exercise to implement a partitioning scheme using MPI or even a low-performance messaging library (or even just optimize for cache sizes on a single device, with no network transport).
Like the transition from the elegant, 5-character Laplace equation to the relatively verbose and complex numerical Julia solver, there is an additional and necessary step in making the numerical solution further scalable with present technology. In particular, the notion that the computational boundaries map nicely to the physical boundaries must be thrown out, because now we must respect the layer of "virtual boundaries" between the partitions.
Apropos of nothing, some of my first programming lessons were FORTRAN programs from my dads old engineering textbooks. The book’s graphics showed them being handwritten on graph paper and even showed the punch cards they would ultimately be put on.
One of the most impressive programs solved Laplaces equation for heat flow in a pipe. They used some mysterious plotting library that put ASCII art to draw contour lines and output directly to a line printer. I thought it was the coolest thing ever, but it was hard for a high school kid to understand.
Over the years I’ve thought of writing that program in a modern language, but it was never worth the time and effort to go over that FORTRAN program in detail. Numerical methods are too often explained from the point of view of mathematicians and engineers, and not computer programmers.
The blog post here is 1000x more readable and much higher quality and does a lot to demystify the subject. I especially like his progression from simple brute force methods to more efficient solutions…which is the natural way to learn. His comment about “Laplace’s equation just means every point is the average of its neighbours” is perfect.
Believe or it not I was in need of just such a tutorial … for something I’ve been thinking about at work. His article really hit the spot and I’m grateful for it.
It is easier to study from a theoretical point of view (easier that the heat or the wave equation: [1], Ch. 2), and it's easier to implement a solving method. When you are learning the finite element method, this is one of the first examples that people use to test if they got the right implementation.
Now, I wonder if the author regards it important in his particular area (aerospace engineering), I'm new to the field so I don't see how. Right now I'm reading a book [0] on models to solve problems concerning aerospace applications and they mostly use a simplified form of the Navier-Stokes equations together with some elasticity assumptions.
If you take the divergence of the incompressible Navier-Stokes equations you get a Poisson equation for the pressure, with a function of velocity on the RHS. So it’s important in fluid dynamics.
The opening of this article had me recalling an old TED talk: "People don't buy what you do, they buy why you do it."
Of course, the author here isn't really selling anything, at least not to the lay man. He's writing niche articles for a niche audience. That is to say, not me.
It's a simple and general method that works in many domains, which is an usual combination.
The other ways of solving the example of arbitrary heat sources and sinks on a plate range from hacky combinations of simpler methods, to tedious math, to complicated general methods. If you switch from heat to pressure distribution, you'd have the same types of options, but the specific methods would be different.
Some poor soul wrote a somewhat competent and maybe even lengthy blog post / article about something they really care about and are knowledgeable about. It may be directed at a specific audience, or maybe just screaming into the void to record down some insight they had for themselves to read again later, or similar. And they use a more-than-necessary general title like "the best tool you'll ever see" with "you" meaning either just themselves or a narrow target audience or so.
And then somebody comes along who finds it interesting, submits it to HN, it makes front page, and now it looks like the poor author with their more-general-than-needed title is making a general statement about sth for the changed audience which is the HN crowd, but which is distinctly different from the original target audience.
Case in point: The articles author self describes as: "I'm an aerospace engineer that writes software. I love math and science, and I have two cats."
For an aerospace engineer this all makes a lot of sense and is a super great tool, I'm sure. It's just not for the overall HN crowd. And it's not the authors fault.
I'd rather have more submissions like this on the HN frontpage than the slew of entrepreneurship advice (good or bad), programming-languages-du-jour and disguised content marketing.
Anyway, the premise that "everything I see has to appeal to me" would best stay on YouTube where it originated.
I didn't intend to demand "everything I see has to appeal to me". I was merely pointing out that the meaning and impact of a headline are relative to the target audience and this was an example that illustrated the difference. With the effect that somebody somewhat rightfully asked "eh what is this about again"?
The HN crowd has a different average toolbox than the article's author, so the apparent mismatch between headline and article content was confusing.
It IS a good article, but the audience of the article is fairly specific yet left unspecified.
As a general principal in technical writing it is advisable to start with a "why you should care" statement because this naturally informs the reader about the context.
Is the second section “when would I use this” sufficient to provide a “why you should care statement”? Or is there a more common way to call this out in technical writing? Perhaps an “intended audience” or “necessary prerequisites”?
I mean there is nothing "wrong" with starting at the 2nd paragraph (and that was was just for the more limited Laplace version of Poisson's), its just not generally the most effective writing style. Yes, there is some subjectivity here, but writing is hard, and it is only through criticism that we learn to be better technical writers.
The first paragraph of the conclusion would have better served as the Introductory remark: "Poisson's equation comes up in many domains. Once you know how to recognize it and solve it, you will be capable of simulating a very wide range of physical phenomena." That is a great sentence. I'm interested now, and I know its context.
There should exist a subreddit for exactly these type of articles which are in depth. Who know article like this may want someone to learn something entirely different than their domain and then they end up applying it in their domain in a whole new way.
From the poster sharer username here in HN it seems "the poor author" is also the one sharing it here, so it seems this blog post is at least partly directed to the general HN audience, not like the hypothetical situation you are placing here. So the whole "It's just not for the overall HN crowd" is probably not a valid point?
I found it a throwback to my university years, but I did study Industrial Engineering with thermodynamics, fluid mechanics and whatnot so I did find it interesting. I'm pretty sure it's usable by a bunch of people in HN as well in many fields where software intends to emulate the real world, like designing a smart appliance, games, VR, etc.
What's getting confusing with this discussion is that the title has changed. Now it's just "Poisson's Equation". But before it was "Most Powerful Tool not yet in your Toolbox" which was really off topic for a mainly sw dev crowd.
That the author himself submitted it (under that original title?) would then be his own "fault". But my general original point remains.
Just to point out, it seems like the author themselves submitted the story to HN. Still I agree with your reasoning, but I think slight clickbaity titles do get clicks which is why we keep seeing them.
Yup. This wouldn’t get nearly the same amount of attention if the title were “Poisson’s equation is the most powerful tool in your toolbox for finding steady-state solutions to the heat equation with arbitrarily placed sources”
I tried to skim the article, I started to read comments, and it's only now that I've gotten to yours that I have the slightest idea of what this article is even about.
If it wouldn't get as much attention with that title, then perhaps it isn't appropriate for HN in the first place.
The examples are about heat transfer, because it is an intuitive concept for most people, but as the article explains Poisson's Equation and these methods can be applied to a broad range of problems.
Yes, I would love it if HN had optional descriptive titles as subtitles to the main story titles (which would then always be the title given by the author at the time of submission).
Well said. There is also the other extreme, where articles of the kind you described don't "use a more-than-necessary general title" but one that is so specific and narrow that it will never fly on HN, even if the content is otherwise a good fit for a valuable HN discussion.
The dilemma with titles is that most of them fall into one of two categories:
- titles where the author didn't put much effort into
- titles where the author tried too hard
The first category is often confusing because the article doesn't fit the title well. The second category often ends up as clickbait.
> For an aerospace engineer this all makes a lot of sense and is a super great tool, I'm sure.
The article seems like a decent introduction to the Poisson-equation. But the original title was very misleading.
Because the Poisson-equation isn't some super-useful tool so much as a Day-1 topic discussed in intro-level classes. It's a really simple equation compared to others used in Engineering, Math, and Physics, so it's often introduced as a starting point.
Except prionassembly's post here shows it's WAY more useful than the original "model physical things" of the original article. Also glad this is here, if only to surface such interesting things!
You can also use it to solve labyrinths. Just put a high pressure at the beginning and a low pressure at the end. Solve the Poisson equation. The path through the labyrinth is always the steepest slope. In [1] you can see a small implementation of the idea.
More generally, I believe this is exactly the same as flow-field pathfinding, which conveniently has the property that you end up with a solution to the whole map -- so you've solved all pathfinding for all entities anywhere in the map, in one shot. Great for hosting a ridiculous amount of entities on a static (or slow-changing) map.
Brogue's creator also "invented" djikstra maps, which I believe is also exactly the same[0][1], to handle AI strategic pathfinding (e.g. avoid hazards while reaching treasure).
In Game AI Pro (I forget which article/book), someone suggests taking AI preferences (e.g. hunger, health) and computing a flow-field per preference (e.g. a food-map, a danger-map, etc), and multiplying the values against the preference to act as a weight (so food-map * %hunger, danger-map * %health), and summing the maps together to produce the final map used for pathfinding. Notably, the food-map can be shared by all entities consuming the same kind of food -- only the weight has to be re-calculated, and the final sum.
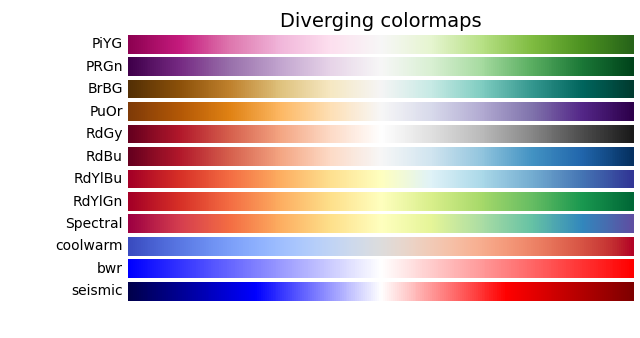
> It is customary when simulating heat flow to use a wacky color palette where red is hot and blue is cold, with all kinds of intermediate colors in between
In an otherwise excellent article, this is the only issue I could find. We really need to stop using/recommending/normalizing rainbow color maps (i.e. jet). They actively confuse readers by creating visual artifacts that aren't actually in the data.
This article has some great explanations and visuals.
The original post uses a rainbow color map to represent temperature-related things because having a diverging color map is often a useful intuition for temperature heat maps. But in that case, we should prefer one of the following diverging color maps listed on the matplotlib site (this list definitely isn't exhaustive, but it is helpful).
Can not agree with this more, if people want to plot something that is linear please use a perceptually linear colormap! Just a one second glance at the Mona Lisa in rainbow/Jet is enough to make you gouge your eyes out.
https://peterjamesthomas.com/2017/09/15/hurricanes-and-data-...
For a more technical description the information behind the newer matplotlib defaults, particularly the scipy talk, is great.
https://bids.github.io/colormap/
And for those that do not like the matplotlib options, colorcet provides a wider range of alternatives that are not trash (unlike Jet)
https://colorcet.holoviz.org/index.html
Here is my implementation in python of the Poisson equation on an arbitrary 2D domain using the finite element method. I used this for teaching a course in partial differential equations:
I have used Poisson’s Equation recently. Actually, something similar. Been coding up some thermal conductivity calculations form scratch.
What’s nice about the Laplace equation is that there are some exact analytical solutions in some situations which is really helpful for validating numerical codes and sanity checking. It’s also simple enough to implement in an Excel spreadsheet, Color coding the cells to indicate temperature. Good sort of “no code” example of the concept.
Since you have written it as a symmetric, positive definite, sparse linear system, why don't use a standard solver like CHOLMOD which is available in Julia? (and behind octave's anti-slash operator). It should be faster than the ad-hoc single-scale Gauss-Seidel.
While CHOLMOD is great, you cannot always use the Cholesky factorisation when you solve PDEs. For real-world simulations, we often have to solve systems with hundreds of millions, if not billions, of equations and in then case, even a highly optimised direct solver like CHOLMOD fails. The fill-in simply becomes too large.
For these small test cases, however, simply using CHOLMOD (or any other sparse solver) would do the trick perfectly.
At the end the author mentions there are a large number of methods available for solving. Also mentions there are a much larger set of applications that those discussed.
The goal of the article is educate on the mathematics, not a tutorial on how best to do mathematical modelling with Julia. An article like that is better served explaining the inner workings of the Black Box, rather than just using the Black Box.
Why? The goal of the article is not to be a Julia tutorial. Julia is just a convenient demonstrator. Better to make the code as language independent as possible.
It's the common way to solve a linear system in octave, matlab and julia.
You have an invertible square matrix A, a vector b of the same dimension, and you want to find a vector x such that "A*x=b". Then you write "x=A\b", which is like "x=A^(-1)*b" but does not get to compute the full inverse matrix (which is useless).
Sorry, yes I know about the syntax. I'm just struggling with what exactly you would be plugging in. Like with respect to any of the example problems given, what would A and x and B be?
You create matrices that represent the operator. For instance, suppose you had a 1D function and were interested in the evenly spaced points (x1, x2, x3, x4, x5), with the function values at these points being
y1
y2
y3
y4
y5
If the differential equation had a first derivative in it, you'd construct something like this, multiplied by some constant (e.g. 1/(2*dx) for an unscaled derivative):
So the derivative at each element is defined by the difference of the next and previous elements. Multiplying the column of function values by this gives you the derivatives. This doesn't work for the first and last element, and in fact you'll usually modify these rows depending on what boundary condition is needed, so I've just left them filled in with "?".
For a solver, you don't know what the y values actually are, so you construct a column that corresponds to the right side of the differential equation. For instance, if the equation was something like the trivial dy/dx = c and you were using the operator above the column would be
?
c
c
c
?
with the first and last values to be filled in based on the boundary conditions. You then left matrix divide that by the operator matrix (i.e. multiply it by the inverse of the operator matrix). That gives the solution to the equation.
This is just a simple example and in practice the matrices will be larger and more complex.
A is the five-point laplacian (a symmetric matrix with five non-zero diagonals), as implemented in the "step" function in the article, let's call it L
b is the datum h
If you set-up the sparse matrix L and the vector b (with the same code that performs the iterations in the article), then you can solve Poisson equation "L*f=h" by doing "f=L\h".
It's not some obscure symbol; it's just division. It just so happens that we typically "divide" matrices from the left when solving equations like this (and matrix "division" isn't commutative) so instead of `a/b` it's `b\a`.
Yes I know. It’s a solve operator…it’s equivalent to division only in the infinite precision world.
The \ operator differs from the / operator in that it doesn’t compute an inverse … it solves the system of equations. Solver algorithms are more numerically stable ( in that you’re much less likely to have large errors due to wacky input data).
I'd just say that solving the system of equations is the best way to divide by a matrix — that's why I put air quotes around "divide" above. In Julia, right-dividing matrices (with `A/B`) actually does the smart adjoint-commuting thing to left-divide it and do the solve (with `(B'\A')'`).
using LinearAlgebra, SparseArrays
N = 10
D1 = sparse(Tridiagonal(ones(N-1),-2ones(N),ones(N-1)))
Id = sparse(I,N,N)
A = kron(D1,Id) + kron(Id,D1)
You just use the Kronecker product to build the matrix in the different directions. This, along with the relationship to convolutional neural networks, is described in the MIT 18.337 course notes: https://mitmath.github.io/18337/lecture14/pdes_and_convoluti...
Wow! It seems you have the magical capacity to ingest the reference to an equation and instantly derive an intuition for how it works and what it's useful for. Learning technology this advanced has never been seen before by humankind, I hope you share it with the rest of us!
Everything being referenced is stuff you'd learn in a typical technical education as part of either calculus or statistics. Your reply comes off as of defensive in a way that implies that you're shocked some one would know any of this stuff.
My reply stems from enriquto's misunderstanding of the purpose of the article, which is the "typical technical education" itself. It's like they are wondering why the article even exists, and isn't just a one line reference to the julia docs. Clearly there's nothing wrong with already having specific knowledge of a subject, but questioning the purpose of technical education because you already have it is bizarre.
Maybe an analogy would better explain my perspective. I imagine that
enriquto would greatly appreciate my latest article, reproduced in its entirety below:
Sorry for the misunderstanding, then. It was not at all my purpose to disparage this article. It is a lovely article and very clearly written and illustrated.
I'll state my point following your json parser example. If you write an article about the implementation of several json parsers, you may still want to call JSON.parse at the end, as a sanity check that your implementation is working. The function is right there and you may as well say that!
In the present case, since the author has already set-up explicitly Poisson equation as a linear system of equations, it would make sense to call julia's built-in solver. (If only to marvel that it is much, much faster than the simple methods shown before, thus it must make some really fancy stuff inside!)
I agree with your point that it may be valuable to the reader to also mention common libraries or built-ins that solve the same problem that was discussed in the article somewhere near the end. More generally, linking to sources, docs, related work, or next steps can be very nice for readers to further their education. Framing your original comments with "the author should also mention... a standard solver like CHOLMOD" or "a standard solver like CHOLMOD ... as a sanity check that your implementation is working" as you described would have had a good chance of preventing our communication misfire and avoiding my (perhaps unnecessarily strong) snark.
Numerical solutions of PDE are hardly studied in a typical technical education in calculus (it requires more theoretical machinery) or statistics (PDEs in statistics is somewhat narrow and specialized).
I've never worked with multi-grid, but I assume the preconditioner is also based on the Cholesky factorization? Incomplete Cholesky was pretty effective as the preconditioner for the pressure solve in my toy fluid sim.
Great post, one nitpick -- I wouldn't say that a matrix is a "sparsely defined" function, but rather a function defined on a finite grid. It might also be worth pointing out that same approach works for any graph, not just a grid.
Also, what's confusing is that algebra usually uses matrices to describe linear functions from n-dimensional to m-dimensional vector spaces. Matrix has n rows, m columns, you give it an n-dim vector and after matrix multiplication you get back an m-dim vector.
The author uses a matrix quite differently. You give it two integer coordinates i and j and it gives you the value at position (i, j) back. That's a valid use, but not quite what you'd expect in a math-oriented article.
Thanks for calling this out, I thought it might cause confusion. Matrices are super weird objects because they don't fit nicely into the {scalar, vector, function, operator} classes that maybe we're used to. A matrix is a function in that it can take in a vector and map it to a new vector. It is also an operator in that it can take in some other matrix (a function!) and give you a transformed matrix (a new function). It is also a function in the sense that it can map vectors to scalars, where the input vectors (x, y) are the coordinates and the scalar stored there is the output. All of this gets further complicated by the fact that the elements of a matrix can be scalars, complex numbers, or even matrices! They are really strange objects and maybe I'll write up a whole post just about that strangeness.
Just writing down the connections here for myself and maybe others:
A matrix represents a linear function taking a vector and returning a vector, written as
w = M v
Matrix multiplication corresponds to function composition.
Vectors can be indexed, and we can view them as a function i -> v[i] defined on the indexing set. We can also define basis vectors b_i, such that b_i[j] is 1 at index j=i and 0 otherwise. Any vector can be written as a weighted sum of basis vectors, with the vector components as coefficients:
v = Σ_i v[i] b_i
where Σ_i represents summation over the index i.
Matrices can be indexed with two indices, and this is closely related to vector indexing: For a matrix M, we have
M[i, j] = (M b_j)[i]
Each column of the matrix represents its output for a certain basis vector as input.
By writing a vector as a sum of basis vectors and using linearity, we get the well-known matrix-vector multiplication formula:
Here's a concrete example. The first matrix in the post is f = [[1, 1, 1], [1, 1, 1], [1, 1, 1]].
In linear algebra, we would interpret this as a linear map. A true equation would be f([1, 2, 3]^T) = [6, 6, 6]^T (where I'm using ^T to mean "transpose to a column vector").
But here, the author means f(1, 2) = 1, i.e. the (1,2) coordinate of the matrix is 1.
And interestingly, both are connected. If d_i somewhat hand-wavingly expresses the vector d_i = (0, ..., 0, 1, 0, ... 0) with the 1 at position i, then given matrix M you can do
f(i, j) := d_i^T * M * d_j
The RHS is using classical matrix multiplication, and the function value will be the matrix' entry at column i, row j.
> From here we could use Bernoulli's equation to find the pressure distribution, which we could integrate over the surface to find drag and lift and so on. With a few tweaks we could simulate rotational flow, vortex panels, real wing profiles, and so on.
> With just a few simple building block we're already edging up on real computational fluid dynamics. All this just by adding up some matrices!
Correct me if I'm wrong, but the only "real" CFD you could solve with this are incompressible potential flows [0]. Solving Navier Stokes is clearly not just "a few tweaks away" from the Laplace equation, but I would be curious which tweaks would take you to e.g. rotational flows.
I could have used this 32(!) years ago when I was struggling in college. (This and 3b1b.)
It amazes me just how many key topics were so inaccessible to the majority of the class at engineering school. I base this on observations from group study sessions and the hyper-aggressive test curves.
I knew lots of people who never got the hang of div/grad/curl, or a Jacobians, or eignenvectors, or Z-transforms... These are key engineering concepts, you'd think colleges would bend over backwards to make sure these concepts are learned as succinctly as possible rather than add a curve to a test that makes a 23 out of 100 an "A" grade.
I'm digressing, and complaining, but the counter argument has always been: you're not supposed to learn everything in college, you're supposed to learn how to learn. Sure, right, but who has time to keep learning advanced calculus after college? (Well, I still study math & physics for fun, but over the course of decades, not years.) Not being able to see the world through these lenses I think means missing key engineering perspectives and relationships.
I feel the same. How can it be that I went to a world famous institution providing 2-to-1 student-teacher ratios, but I still think the best explanations are these modern internet explanations? I guess the best explanations just bubble up in the modern environment.
> you're not supposed to learn everything in college, you're supposed to learn how to learn
But to learn how to learn, you gotta learn some things to a somewhat decent degree. I think at some point you need to have these linalg/divgradcurl things down, if only briefly. You might forget any particular topic, but if you've indexed it you should be able to pick it up again, particularly in the modern learning environment.
Just imagine coding without access to StackOverflow.
Interesting to think a bit about student/teacher ratios (STR).
The up-side is that with a low STR (2:1), the teacher can adapt to the particular strengths and weaknesses of the students, to get the best reinforcement. The /downside/ is that the students will typically also have fewer teachers overall, and are maybe stuck with a bad one. (This is the problem of bad grad school advisors in a nutshell...) In this world, teachers are very expensive, though, so we end up with students competing for access to good teachers, by paying super-high tuitions, dedicating their early childhood to olympic-level basketweaving, etc.
In the medium-STR regime (30:1 or 100:1), we get the worst case: There's no teacher adaptation to individual students, but teachers are still the bottleneck.
The internet has something to say about extremely high STR (1MM:1). In this regime, things flip and any teacher can teach every student: Teachers are no longer scarce, and so have to compete on giving the best instruction. Instruction quality increases as a result. And on the flip side, there's no student competition, which /maybe/ causes student quality to drop.
Not maybe. Absolutely. Even paid-for online courses have a relatively high drop out rate.
But that's okay. It's the price to pay to achieve the volume needed to pay for great instruction. I can take a music theory class from an instructor who would never waste their time teaching someone like me. Even though I may not get much more than entertainment value from it. I'm effectively subsidizing the students who do learn something concrete from the course.
There might be an argument to be made that pandering to an "edutainment" crowd might reduce the quality of instruction, but a good instructor should be able to find the right balance.
The latter regime is less a function of the ratio itself and more a function of the total number of accessible teachers, and the ability to switch teachers at will to find the one most suited to your learning style. If a university had 100 teachers all teaching the same course in the low or medium STR regimes and students were able to easily swap between teachers at will, the effect would be the same.
The ratio is really what matters more than absolute numbers; it tells us where the bottleneck is (supply or demand).
If the STR is 2:1 and you've got 1000 teachers, it means you've got 2000 students. If only 5% of teachers are good (see: sturgeon's law), you've still got competition centered on the student side, as 2k students fight to get into the classes with the 50 good teachers.
Ah, I get your point now. In my hypothetical example, you could still have those 2000 students enrolled with only the 50 good teachers. The overall STR would still be 2:1, but most of the teachers would have no students, so the effective STR would be 40:1.
The main thing distinguishing online education is the ability for students to all flock to the good teachers and completely abandon the crappy ones.
> Just imagine coding without access to StackOverflow.
That was the beginning of my career in the PC industry!
C compilers for PCs were in their infancy, so all of the code I was writing was x86 assembly using MASM 6 on MS-DOS 5.2 (hello TSRs and config.sys).
I forget the company, but some tech house published a giant 500 page PC encyclopedia every year that listed all of the x86 CPU instructions, IO ports, interrupts, DOS interrupts, etc. The last issue I had was white with pink lines on it and weighed about 3 kilos! Then the internet showed up and that all went away.
Well, except the mentors. Mentors will always be a step-function way to learn new material.
Turns out that mathematics pedagogy is poor, in general. Especially for geometry and vector calculus, where it's either obsolete, busted systems or incredibly abstruse ones.
Skipping over div/grad/curl and Gibbs-Heaviside vector calculus by going straight to differential forms and Clifford algebras (geometric calc) would save a bunch of heartache and pointless effort.
Linear algebra is essential since the whole point of differentiation is to construct linear approximations of functions...among other things.
It's not that there aren't massive lectures, tutorials are in addition to those.
Not bad value actually, despite what I said earlier. You do get to ask about whatever your mental block is, and the tutor is gonna know. But studying is time consuming, an hour is not as much time as it seems. You probably learn the most on your own, which nowadays ought to mean on the internet.
The answer is statistics: what is more likely, that the best explainer of a certain topic is within a group of people you have access to, or that person is somewhere else in the world?
This is very analogous to the problem industrial research groups face trying to answer a certain problem, e.g. ‘how do we ensure that our team is the most likely to solve a particular problem first?’
This is why start up acquisitions are so common even among the best funded tech companies.
Might also have something to do with the explanation size: this Poisson thing is one little thing. With the internet, it's perfectly acceptable to just do a blog post on one little thing.
Previously, if you were to write a textbook or teach a tutorial, you needed to teach a bunch of things.
So in the internet age there's a bunch of fine grained "best explanations" coming from a variety of authors that beats the best that one guy can do across a range of topics.
You are assuming that the best explanation can be given without interaction. I don’t have to be a great explainer but only have enough social skills to do an iterative search thru explanations, using my learning friends face and questions as metric, and find a very good explanation for that person at that time. If but only if they missed some but of linear algebra, i can sketch it out. And while
Many people learn well by listening and note taking, many others also
learn well by doing. We have documents and so on at work but when I see a good PR then I know the message is understood.
Start ups are better than large companies not because the people are so much smarter, but because the structure enables for so much more rapid learning and search of the solution space.
Agreed! It's one reason I'm bullish about our children learning and applying math better than us.
Btw, 3 Blue 1 Brown's videos on linear algebra [1] are similarly awesome and of course his video on Fourier is magnificent [2]. Another awesome math explanation is on game theory by Nicky case [3].
30 yrs ago the internet was still in its infancy and good engineering teachers were available to only a chosen few and closed out to the rest of the world.
I stayed curious and learning. Better and better teaching methods became accessible thanks to the maturing internet. I started to understand ideas in engineering much better.
Alas, there is no way I can express this progress in a resume but learning and understanding satisfies my curiosity.
>I could have used this 32(!) years ago when I was struggling in college.
I was struggling with this material more like 15 years ago, but same. I wish someone had explained the LaPlacian like this when I was in Multivariable calculus:
>Find me a function f where every value everywhere is the average of the values around it.
It's so simple and easy to grasp, yet provides so much insight into what's going on when you're doing the actual calculation behind the operation, but is so easy to lose sight of when you're overwhelmed with figuring out the 'mechanics' of it and everything else that was covered in the day's lesson plan.
Obviously depends on the school, and how much grade inflation (or deflation) they've gone through. When I studied Electrical Engineering, class average was 2.8 or so. The few students that actually had anything close to a 4.0 were terrific students.
I remember in our real analysis class, the professor started with a comment (to the class) in the lines of:
"This is a demanding class. Top performing students usually spend 25-35 hours a week on the problem sets alone, and top grades are rarely awarded - some years there are zero A's. Please take the weekend to consider if you really need or want to take this class."
FWIW, this was no top University - but then again, grade inflation is not that bad in STEM, from my experience.
Hmmm. I took a real analysis class at UNC Charlotte and one at Oxford and the latter one transformed my understand of maths. I felt if I ever taught a “maths for humanities” class Lebesgue integration and measure theory would be key components. I think if they are taught well by a person that really understands it backwards and forwards, well enough to explain it like a physicist, it is accessible.
That's not true at all. When someone drops 200 resumes on your desk and says, "Find 10 candidates to interview by tomorrow", you need some initial sort criteria.
The truth, my criteria were: #1: university, #2: GPA, #3: keywords. Sure, I was bitten a few times (I hired an MIT master's student who was utterly helpless), but over the course of years doing this, some patterns emerge, and high-GPA absolutely correlates with good candidates.
Sure, there might be a 2.0/4.0 who is a whiz, but sorry charlie, I'm not gonna picky your resume, so apply yourself or start your own company, because a low GPA means you don't give a shit or have some other problem.
I agree that GPA is useful as a binary indicator—if it’s abominably low, like a 2.0 in your example, it’s a red flag. But a 4.0 is no more predictive of being a good hire than, say, a 3.3. It’s also very school-dependent. Some places inflate grades a lot more than others.
In my own anecdotal experience, I omitted my GPA entirely from my CV when looking for jobs straight out of college and got interviews at every single place I applied. It’s not nearly as important as a lot of people think.
> But a 4.0 is no more predictive of being a good hire than, say, a 3.3
Ironically I graduated with a 3.4, and I did feel guilty for not passing on resumes with GPAs as low as mine. But as I said, when I had many other tasks to do for work, and then had to stop them all to sort resumes (we all took turns), it was hard to justify excursions when there were so many 4.0s. It is a sad truth that new college grads almost all look the same on paper...
For me at least, at a large public university with a highly-rated engineering department, it mostly came down to math courses being taught by TAs/new faculty who were not primarily interested in teaching.
When I had actual engineering dept courses on these topics (frequency domain comes to mind), I grok'ed it pretty quickly. But the math lectures were basically spent doing practice problems from the book, without any sort of insight or practical application.
The generation growing up today is the first that can broadly learn mathematics from mathematicians rather than from teachers, and we should encourage them to do so.
When I was 12-16, I was interested in physics enough that I would study it in my free time just for fun, solving problems from the Physics Olympiad. I could solve lots of the problems with just intuition, until I stumbled upon the sliding chain problem. I spent about a week pondering over it with no results. I approached my math teacher. He admitted defeat and referred me to the physics teacher. If I remember correctly, the physics teacher avoided admitting he didn't know how to solve it and didn't give me any pointers. That was the last Physics Olympiad problem I tried to solve, after dreaming of attending the competition for years (I should mention that at that time my primary interest already were computers; physics was just a hobby). I wonder whether this could still be a problem today when anything can be found on YouTube. There's a lot of noise, too. How long does it take the average curious kid to find the signal that is 3b1b, MIT OCW, etc?
It is certainly much easier. But if that kind of self study culture doesn't already exist in one's own school, either encouraged by teachers or classmates, it may take a much bigger leap to discover that material.
> you'd think colleges would bend over backwards to make sure these concepts are learned as succinctly as possible rather than add a curve to a test that makes a 23 out of 100 an "A" grade
School is not about learning. It's about money. Seating as many students as possible for as long as possible to suck in as much student loan money as possible. For this you need to be a prestigious school. Of course they want to boost their grades.
These are the people who have the gall to claim a moral high ground when they find and punish "cheaters".
What's a "test curve"? How does it make 23/100 be an A grade, is it some kind of CDF-based transformation that makes certain % of students pass the test?
Unlike in high school where the grade percentages are pre determined. ie a 90% is the cutoff for an A and it is expected that students will score that or higher, College professors see that as making the test too easy with the potential of having too many students get A's. Instead they will make the test longer or harder such that the best grade is 60/100 and the average grade is around 40. The will then scale things such that the top 10% get A, 20% B etc.
Sometime the prof screws up and the test is too hard where the aveage grade is 30. Sometimes some over-achieving git 'busts the curve' and scores a 95 and the next highest grade is a 60 - making it hard for the prof to justify giving A's to the top 10%
That sounds like what it is from my experience as well but it's really up to professor.
One exam was really hard such that your new grade was sqrt(#correct/#total). Another was to make new total the value of highest correct score, e.g. everybody in class got 0-20 out of 100, new total is 20.
Your 30 years of experience is why the article makes so much sense. If you saw this in college you wouldn't have also learned everything else about div and grad.
> these concepts are learned as succinctly
?
Succinctness is *why" you didn't learn multiple interpretations of everything.
> ? Succinctness is *why" you didn't learn multiple interpretations of everything.
Good catch. I think that was the wrong word because I was learning s-transforms in three classes sophomore year: differential calculus, linear systems, and thermodynamics. It was the opposite of succinct because the same concept was being thrown at me in three different classes from three different perspectives.
to throw one other, maybe-less-obvious, spin on it:
When you take a class, you see one wrong way to do things. When you teach a class, you see fifty wrong ways to do things.
Puzzling through all the different wrongs ways to think about a problem really helps cement the core ideas... And first-year calc students are masters of creating interesting-but-wrong interpretations.
> This oval (called a separatrix) has the special property that no wind flows through it at all. It acts just like a solid surface. We have already assembled a reasonably accurate simulation of how air flows around an ellipse in some confined space like a wind tunnel!
My understanding of airflow simulation (undergrad-level at best) is that the correct boundary condition is almost without exception the no-slip one: air should be stationary at the surface of each object, not just have zero flow across it.
Am I correct that the calculation mentioned above really only applies to the "dry liquid" scenario where there is no drag and zero viscosity?
You are correct! The simulation as written does not handle the no slip condition. The simulated "air" is inviscid and irrotational. You would need to tackle a few more things in order to have a really accurate simulation.
Beautifully done. Everything was clear and intelligible.
I have a CS background, but no physics/aerodynamics background. What are the minimum additional steps beyond this tutorial which could produce an aerodynamically correct 2D wing simulator? (With turbulence, not a steady-state solution.) I've come back to tackle this topic intermittently but have never cracked it. To anyone with expertise here who could share an overview and links, I'd be grateful.
But that won't handle turbulence. The real "turbulence problem" is that computing actual turbulent flows requires enormous computational resources. So instead of solving the Navier-Stokes equations, related equations with lower computational cost are solved. Because of how these equations are developed, they require modeling of "unclosed" terms, and this is a likely source of inaccuracy.
If you want something relatively simple, you could take the RANS approach and use the Spalart-Allmaras model:
Always looking to interrelate my knowledge that sometimes appears to more disparate that I care to consider. The simplicity of considering a matrix function in this way is very elegant. This type of methodology can help demystify some of the earlier steps in modeling by adding a simple intuitive picture that encourages a connection to calculation from the get go.
I too hate the coloured plots but I can tell you as a Stress & Structures engineer who works with ANSYS regularly, it does help when assessing material limits and strain energies. This is especially true when you're working with models where temperature is time dependent.
EDIT: I'm leaving this here to help anyone else who might have been confused by this, which I imagine is likely.
What confused me is that the author is not treating the matrix as a function from vectors to vectors, as is the customary way to treat matrices as functions. Rather, they're using the matrix to represent a sparse, regular sampling of a function from vectors to scalars.
---
This article makes no sense right off the bat. Here's the first substantive passage:
"[Laplace's Equation means] Find me a function f where every value everywhere is the average of the values around it ... In this post, when we talk about a function f we mean a 2D matrix where each element is some scalar value like temperature or pressure or electric potential ... If it seems weird to call a matrix a function, just remember that all matrices map input coordinates (i,j) to output values f(i,j). Matrices are functions that are just sparsely defined. This particular matrix does satisfy Laplace's equation because each element [of the matrix] is equal to the average of its neighbors."
The values of a function are the outputs it maps its inputs to. The elements of the matrix are neither inputs nor outputs.
{kind=link}
Edit - it looked something like this:
https://thumbs.dreamstime.com/b/broken-badminton-racket-phot...